Lesson 12: Languages of North America
Learning Objectives
After finishing this lesson, you should be able to:
- identify the names of major language families from North America
- describe in general terms the loss of linguistic diversity resulting from European colonialism in North America
- identify examples of, and interpret the phonetic symbols for, glottalized speech sounds, in particular ejectives
- describe what makes a language polysynthetic and calculate a synthetic index if given a sample text and three-line gloss
- describe the property of evidentiality and identify instances of evidential morphemes in North American languages
Reading Assignment
Reading
Reading Guide
This reading is the introductory chapter from a large book on indigenous languages of North America. The author, Marianne Mithun, is a well-known specialist of Native American languages.
Background Information
- The term genetic diversity, first on page 1, is being used in the specialized sense of historical linguistics. Related languages are said to be genetically related; this has nothing to do with biological genetics. Genetic diversity in linguistics simply means diversity of language families.
- The terms structuralist tradition and generative tradition (first on pages 9-10) refer to theoretical models for understanding and interpreting language structure. Their details need not concern us in this course.
- An argument (first on page 12) in this context is a grammatical term referring to nouns and pronouns and their relationship to various parts of a sentence. For example, in the sentence The flycatcher ate the damselfly, both flycatcher and damsefly are arguments of the verb ate.
Reading Questions
- What are some factors that contribute to the difficulty in knowing linguistic details of the languages in North America around the time of the first arrival of Europeans?
- What is the difference between Edward Sapir’s and Joseph Greenberg’s classification of North American languages? How are they both different from modern classifications?
- What is meant by the term polysynthesis? Is polysynthesis universal within the North American languages?
- What are some general ways in which North American languages differ from each other (and from English)?
Lesson
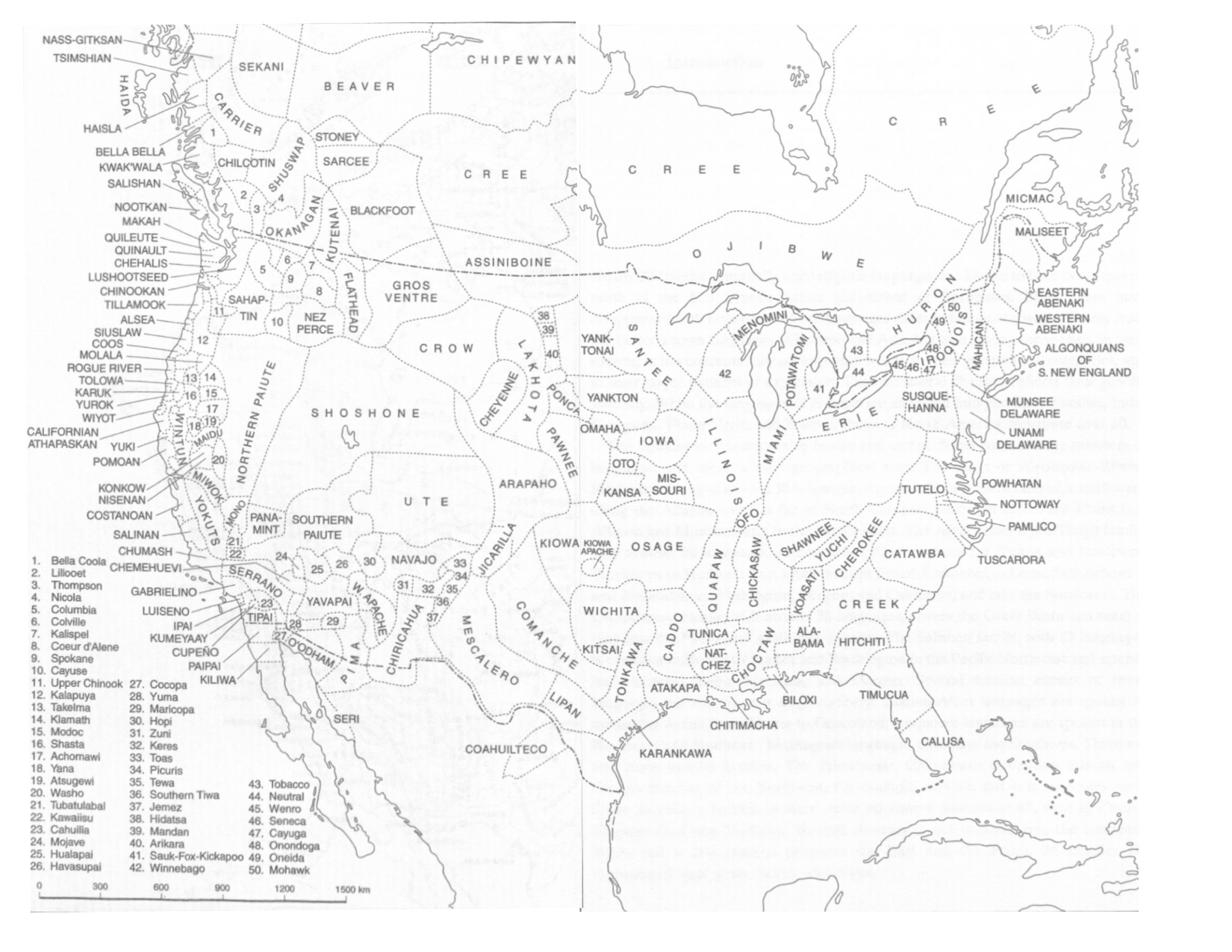
An Overview of North American Languages
One of the pervasive myths about North American culture groups among non-Indigenous Americans is that the cultures—and thereby the languages—form a cohesive group. A common belief is that there is a single “Native American culture,” maybe with minor variants from place to place. This notion could not be further from the truth. Throughout history there have been hundreds, perhaps thousands, of distinct cultural groups residing in North America, each with its own traditions, customs, and languages.